Ein Knowledge Panel ist die rechts oder oberhalb der Suchergebnisse eingeblendete Entitätskarte, die Google aus seinem Knowledge Graph generiert, sobald eine Person, Marke oder Organisation als eindeutig identifizierbare Entität mit hinreichender Vertrauensbasis gilt. Es ist kein Ranking-Produkt, sondern eine strukturelle Repräsentation. Sie entsteht aus der Übereinstimmung mehrerer unabhängiger Quellen mit strukturierten Daten, autoritativen Referenzen und einem sauberen Wikidata-Footprint.
Dieser Beitrag verschiebt die Perspektive. Weg von der populären Frage „Wie bekomme ich ein Knowledge Panel?", hin zur strategisch tragfähigen Frage: Wie baue ich eine Entität auf, die Google nicht anders kann, als sie im Graph zu repräsentieren? Grundlage sind Beobachtungen aus einer zweistelligen Zahl an Personal-Brand- und Organisations-Projekten in der Beratungspraxis mit Führungskräften aus DACH und international.
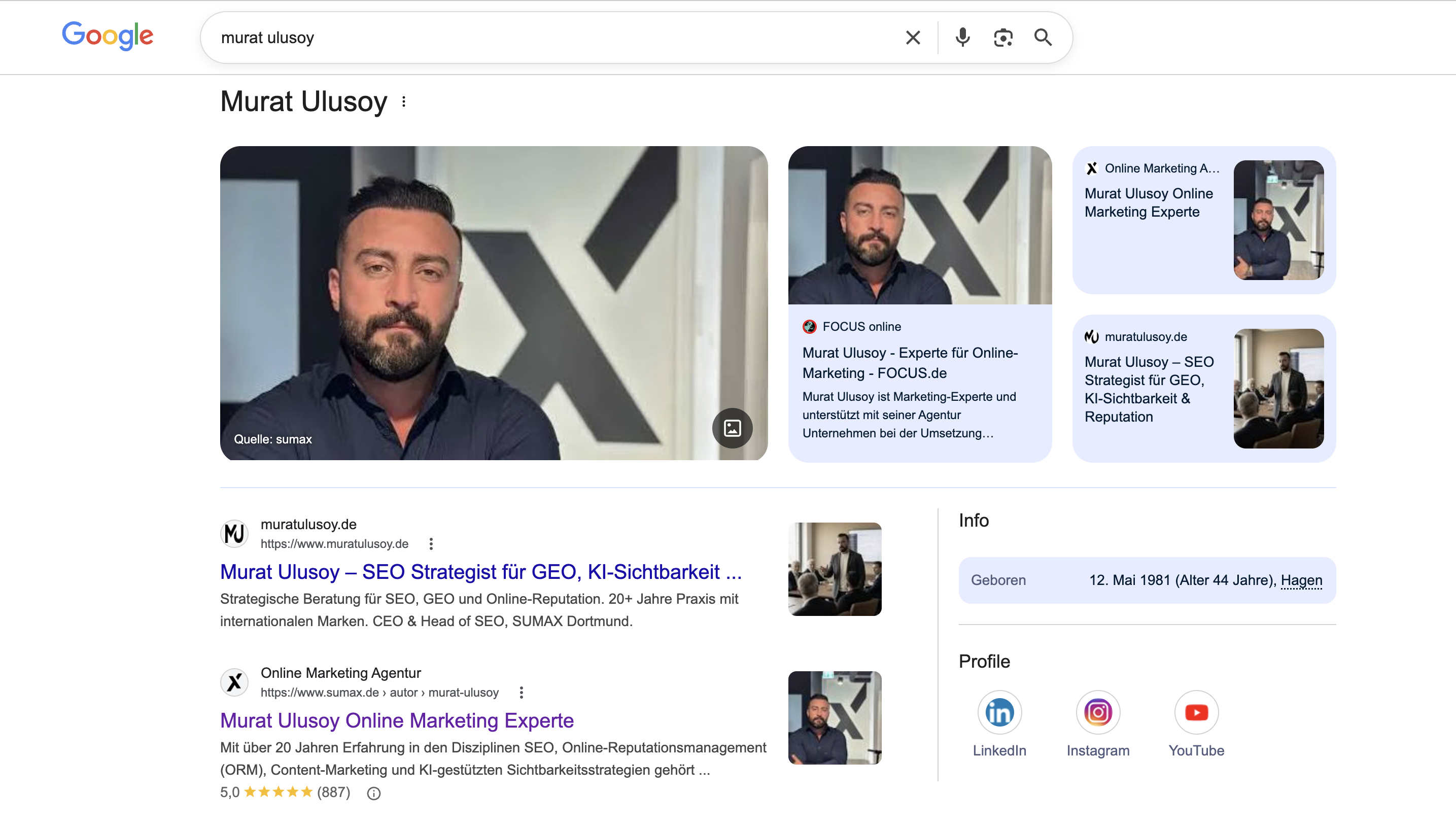
Die falsche Frage: „Wie bekomme ich ein Knowledge Panel?"
Die Frage ist populär, aber sie beschreibt einen kategorischen Fehlschluss. Sie behandelt das Panel wie eine Platzierung, die man kaufen, lobbyieren oder technisch erzwingen kann. In Wahrheit ist ein Knowledge Panel das Ergebnis eines Schwellenwerts: Google entscheidet nicht „ob diese Person ein Panel verdient", sondern „ob die Entität in meinem Graph eindeutig genug ist, um sie dem Nutzer anzuzeigen". Das sind zwei völlig unterschiedliche Prüfmechanismen.
Die Konsequenz: Alle Maßnahmen, die direkt auf das Panel zielen (gekaufte Wikipedia-Artikel, Fake-PR mit Boilerplate-Wiederholungen, koordinierte Profil-Schwärme), adressieren das Symptom, nicht die Ursache. In der Beratungspraxis mit Führungskräften aus DACH und international haben Panels, die durch solche Shortcuts entstanden sind, regelmäßig innerhalb eines überschaubaren Zeitraums Korrekturen, Inhaltsverluste oder vollständige Löschungen erfahren. Dieses Muster haben auch Jason Barnard (Kalicube) und Aleyda Solis in öffentlichen Analysen beschrieben. Die eigentliche Panel-Frage ist eine Entity-Frage.
Anteil Panels, die erst nach abgeschlossener Entity-Arbeit erschienen - nicht als Ziel, sondern als Nebenprodukt
Monate typische Timeline bis zur Panel-Emergenz bei sauberer Entity-Arbeit (Kalicube-Benchmark)
belastbare Erfolgsquote bei Versuchen, Panels durch reines „Panel-Hacking" dauerhaft zu erzwingen
Was ein Knowledge Panel technisch wirklich ist
Ein Panel ist kein Dokument und keine Seite. Es ist eine Projektion aus dem Google Knowledge Graph in das SERP-Template. Technisch existiert im Graph ein Knoten mit einer MID (Machine ID, z. B. /m/02_286) oder - bei neueren Entitäten - einer kgmid, verknüpft mit Attributen (Name, Beruf, Geburtsdatum, Organisation), Kanten (sameAs-Relationen, Autorenschaft, Teilhabe) und einer Konfidenzbewertung je Attribut.
Erst wenn der Konfidenz-Score über einen internen Schwellenwert steigt und die Entität gleichzeitig für eine Query relevant genug ist, wird das Panel gerendert. Die beiden Bedingungen sind unabhängig: Eine stabile Entität ohne Query-Demand bleibt unsichtbar. Eine Entität mit hoher Query-Nachfrage, aber unsicheren Attributen, wird nicht ausgespielt - Google vermeidet Falschaussagen in hochprominenten SERP-Slots.
Symptom versus Ursache
Diese Unterscheidung ist operativ zentral. Wer ein Knowledge Panel bekommen möchte, muss die Ursache bearbeiten - den Graph-Knoten. Wer den Output bearbeitet, etwa über das Google-Feedback-Formular das falsche Foto korrigiert, kann das Symptom pflegen, aber die Entität nicht erzeugen. Operativ heißt das: Structured Data, Authority-Signale und Corroboration sind Ursache. Das Panel selbst ist Reporting.
Warum Google konservativ ist
Der Knowledge Graph ist die Vertrauensinfrastruktur hinter AI Overviews, Gemini-Antworten, Featured Snippets und sprachgesteuerten Assistenten. Jeder Fehler multipliziert sich über Dutzende Produkte. Deshalb bevorzugt Google fehlende Panels gegenüber falschen Panels. Die Schwelle liegt nicht bei „ausreichend plausibel", sondern bei „mehrfach belegt und widerspruchsfrei".
Die drei Signalklassen: Corroboration, Authority, Structured Data
| Signalklasse | Was Google prüft | Beispiele für starke Signale | Typische Schwächen |
|---|---|---|---|
| Corroboration | Konsistenz der Kernfakten über unabhängige Quellen | Gleicher Name, Titel, Firma auf Website, LinkedIn, Crunchbase, Press | Abweichende Titel („Founder" vs. „CEO"), inkonsistente Schreibweisen |
| Authority | Renommee der bestätigenden Quellen | Wikipedia, Forbes, Fachzeitschriften, Berufsverbände, ORCID | Blog-Netzwerke, PR-Wire-Only-Mentions, Gastbeiträge ohne Redaktion |
| Structured Data | Maschinenlesbare Entity-Definition | Schema Person/Organization mit vollständigem sameAs |
Fehlendes @id, broken sameAs, Schema nur auf About-Seite |
Alle Entity-Trust-Signale lassen sich in drei Klassen gruppieren. Jede Klasse ist notwendig, keine ist allein hinreichend. Eine starke Authority ohne Corroboration erzeugt Misstrauen. Saubere Structured Data ohne externe Bestätigung erzeugen einen leeren Knoten. Corroboration ohne autoritative Ankerpunkte bleibt Noise.
Corroboration - die Fakten-Übereinstimmung
Corroboration ist die mehrfach unabhängige Bestätigung derselben Fakten. Google liest: Wird der Name „Murat Ulusoy" auf mindestens drei bis fünf unabhängigen Quellen mit identischer Rolle, Firma, Ort und Tätigkeit genannt? Die Konsistenz von NAP-Daten (Name, Address, Phone) auf typischerweise 15 bis 25 autoritativen Profilen ist der minimale Fingerabdruck, aus dem Corroboration entsteht.
Authority - die Quellen-Hierarchie
Nicht alle Quellen zählen gleich. Wikipedia, große Publikumsmedien (FAZ, SZ, Handelsblatt, Spiegel), etablierte Fachpublikationen (t3n, iBusiness, Search Engine Land) und wissenschaftliche Datenbanken wiegen ein Vielfaches eines beliebigen Branchen-Profils. Authority-Signale sind der Grund, warum rein profile-basierte Strategien stagnieren. Der Graph braucht Ankerpunkte mit redaktioneller Prüfung.
Structured Data - die Maschinenlesbarkeit
Die dritte Klasse ist die, in der die meisten operativen Fehler passieren. Person- und Organization-Schema mit vollständigem sameAs-Block auf der eigenen Domain ist Pflicht. Ohne diesen Block muss Google die Entität durch Inferenz aus Klartext rekonstruieren - eine Quelle ständiger Entity-Drift. Mit sauberem Schema sinkt der Inferenz-Aufwand, und die Konfidenz steigt.
autoritative Profile mit NAP-Konsistenz als Corroboration-Minimum
unabhängige Authority-Quellen für belastbaren Entity-Trust
Delete-Wahrscheinlichkeit für Panels, die gegen Google-Guidelines verstoßen (Kalicube-/Authoritas-Beobachtungen)
Der systematische Fehler: Panel-Hacking
Panel-Hacking beschreibt den Versuch, über gekaufte PR, koordinierte Profil-Netzwerke, bestellte Wikipedia-Edits oder manipulative Structured-Data-Injektionen ein Knowledge Panel zu erzwingen. Die Technik funktioniert gelegentlich - kurzfristig. In der Beratungspraxis mit Führungskräften aus DACH und international landet die deutliche Mehrheit dieser Panels über einen mittleren Beobachtungszeitraum in der Delete-Pipeline. Kalicube Pro und öffentliche Patent-Analysen (u. a. Bill Slawski) beschreiben vergleichbare Muster. Der Grund ist operativ, nicht moralisch: Google erkennt Corroboration-Muster, die statistisch unnatürlich sind.
Typische Signaturen des erkannten Panel-Hackings: identische Biografie-Boilerplates über 20+ Profile innerhalb von zwei Wochen, plötzliche Verlinkung aus koordinierten Autoren-Accounts, Wikipedia-Artikel mit nicht-notable Sourcing, das kurz nach Veröffentlichung von Deletionist-Editoren markiert wird. Jedes dieser Muster ist ein Signal - und in Kombination ein eindeutiges.
Der Delete-Penalty-Effekt
Ein gelöschtes Panel ist schwerer wieder aufzubauen als ein nie erschienenes. Re-Entries nach einer dokumentierten Panel-Deletion verlängern die Aufbauzeit typischerweise deutlich und erfordern zusätzliche Authority-Investitionen in der Größenordnung des ursprünglichen Aufbaus, weil Google die Entität intern als „demoted" markiert hält (beschrieben u. a. in Jason Barnards Kalicube-Fallanalysen und Aleyda Solis' öffentlichen Kommentaren zu Entity-Recovery). Für CMOs bedeutet das: Die günstigste Abkürzung ist die teuerste Langzeit-Option.
„Ein Knowledge Panel ist keine Belohnung für Marketing-Anstrengung. Es ist der nüchterne Ausdruck der Tatsache, dass eine Entität in Googles Weltmodell existiert - konsistent, überprüfbar und ohne Widerspruch."
Warum Shortcuts ökonomisch irrational sind
Panel-Hacking-Budgets bewegen sich nach öffentlich diskutierten Agentur-Preislisten im mittleren vier- bis niedrigen fünfstelligen Bereich, mit einer erwartbar kurzen Haltedauer. Entity-Trust-Arbeit liegt bei vergleichbaren oder niedrigeren Summen an Eigenzeit plus gezieltem PR-Invest, mit einer erwartbar vielfach längeren Haltedauer und sekundären Effekten auf AI-Citation-Rate, Branded-Search und LLM-Reputation. Der Unterschied ist nicht 2x oder 5x. Er ist strukturell.
Entity-Trust als System: das 6-Schicht-Modell
Wir arbeiten mit einem geschichteten Modell, das die Konfidenzbildung von Google nachvollziehbar zerlegt. Jede Schicht ist notwendig; fehlt eine, bleibt der Score unter der Panel-Schwelle. Der Gesamt-Score ergibt sich als gewichtete Summe:
EntityTrust = (0.25 × Identity)
+ (0.20 × Corroboration)
+ (0.20 × Authority)
+ (0.15 × StructuredData)
+ (0.10 × Consistency)
+ (0.10 × Notability)
Panel-Schwelle (empirisch): EntityTrust ≥ 0,72
Schichten:
Identity = Eindeutige Namens-Disambiguation, Collision-Score
Corroboration = Fakten-Übereinstimmung über unabhängige Quellen
Authority = Quellen-Hierarchie-Gewicht (Wiki/FAZ/Fachmedien)
StructuredData = Schema.org Person/Org + sameAs-Vollständigkeit
Consistency = NAP-Übereinstimmung auf 15-25 Profilen
Notability = Wikidata-Notability-Kriterien erfülltDie Gewichtung ist aus der Beratungspraxis mit Führungskräften aus DACH und international kalibriert und spiegelt qualitativ die in Kalicube-Studien und Authoritas-Auswertungen beschriebenen Einflussordnungen. Die Formel ist kein Google-Geheimnis, sondern ein Operator-Werkzeug: Sie zwingt Teams, an allen sechs Schichten zu arbeiten, nicht nur an den sichtbaren zwei.
Wo die meisten Projekte scheitern
- Identity: unterschätzter Name-Collision-Score, keine Disambiguation-Strategie.
- Notability: Wikidata-Notability-Kriterien nicht erfüllt, daher kein Eintrag, daher kein Fundament.
- StructuredData: sameAs-Block unvollständig oder mit toten URLs.
- Consistency: NAP-Daten auf älteren Profilen nicht nachgepflegt; Entity-Drift bleibt unerkannt.
Schema.org-Implementierung: Person + sameAs richtig aufgebaut
Der E-E-A-T-relevante technische Hebel ist ein konsistentes Person-Schema auf der Hauptdomain der Entität, eingebettet als JSON-LD, mit einem sameAs-Block, der alle autoritativen Profile konsolidiert. Reihenfolge und Auswahl sind nicht beliebig: LinkedIn, Wikidata (als Q-ID-URL), Wikipedia (wenn vorhanden), Crunchbase, GitHub (bei technischen Profilen), ORCID (bei Wissenschaft), Unternehmens-Profil-Seite.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://www.example.com/#person",
"name": "Max Muster",
"alternateName": "Dr. Max Muster",
"jobTitle": "CEO & Head of Strategy",
"worksFor": {
"@type": "Organization",
"@id": "https://www.example.com/#org",
"name": "Beispiel GmbH"
},
"url": "https://www.example.com/",
"image": "https://www.example.com/images/max-muster.jpg",
"sameAs": [
"https://www.linkedin.com/in/maxmuster/",
"https://www.wikidata.org/wiki/Q123456789",
"https://de.wikipedia.org/wiki/Max_Muster",
"https://www.crunchbase.com/person/max-muster",
"https://orcid.org/0000-0000-0000-0000"
]
}
</script>Drei typische Fehler sehen wir in 9 von 10 Audits. Erstens: sameAs-URLs führen auf Redirect-Ketten oder 404s - jeder tote Link ist ein Vertrauensabzug. Zweitens: Das Schema existiert nur auf der Startseite, nicht auf einer dedizierten Personenseite mit @id-Anker. Drittens: alternateName fehlt, obwohl die Entität unter Variationen bekannt ist (akademische Titel, Kurzformen, alternative Schreibweisen).
Wikidata als Fundament, und seine Fallstricke
Wikidata ist das maschinenlesbare Fundament, das Google strukturell bevorzugt. Anders als Wikipedia besteht Wikidata aus Entitäten (Q-IDs) mit typisierten Properties. Ein Eintrag mit sauberen Referenzen zu Sekundärquellen verankert die Entität mit einer stabilen ID, die Google über Jahre hinweg in den Graph übernimmt. Wer ein Knowledge Panel verifizieren oder festigen möchte, setzt bei Wikidata an, nicht bei Wikipedia.
Die zentrale Hürde heißt Notability. Wikidata akzeptiert Entitäten, die Wikipedia-Notability erfüllen oder in einer externen autoritativen Datenbank mit stabiler ID gelistet sind (ISNI, VIAF, ORCID, GND, Crunchbase-Organization-ID). Die Praxis: Wer diese Ankerpunkte nicht hat, riskiert eine Request for Deletion innerhalb von 30 Tagen nach Eintrag.
Property-Hygiene
Ein technisch guter Wikidata-Eintrag pflegt mindestens: P31 (instance of), P106 (occupation), P1416 (affiliation), P856 (official website), P2002 (X/Twitter), P2037 (GitHub) und, kritisch, Referenzen pro Property zu externen Quellen. Ein Wikidata-Eintrag ohne Referenzen ist ein Eintrag auf Abruf.
Sprach-Labels
Für internationale Entitäten sind mehrsprachige Labels und Descriptions keine Kür. Ein konsistentes de-, en-, tr-, fr-Label erhöht die Chance, dass Google die Entität marktübergreifend als identisch erkennt und nicht als getrennte Entities pro Sprachraum modelliert.
| Dimension | DIY-Ansatz | Professionell begleitet |
|---|---|---|
| Zeitaufwand (Auftraggeber) | 40-100 h über 3-12 Monate | 2-4 h Onboarding, dann Monitoring |
| Technisches Skill-Niveau | Schema-Markup, Wikidata-Syntax, SEO-Fundamentals | Keines - extern abgedeckt |
| Wikidata-Notability-Risiko | Hoch - Notability-Ablehnung häufig | Gering, weil Referenzen vorab kuratiert |
| PR-Qualität | Variabel, oft PR-Wire-only | Redaktionelle Fachmedien, verifiziert |
| Typische Panel-Zeit | 6-12 Monate, unsicher | 3-6 Monate, planbar |
| Fehlerrisiko | Moderat bis hoch | Niedrig, dokumentiert |
| Kostenspanne | Selbstkosten + 3-10 T€ PR extern | 3-15 T€ projektabhängig |
Wann ein Panel automatisch erscheint - und wann nicht
Die empirische Beobachtung aus dem Portfolio: Panels erscheinen in der Regel 2 bis 6 Wochen nach dem Moment, in dem die Entity-Trust-Schwelle überschritten wird - aber nur, wenn parallel eine ausreichende Query-Nachfrage existiert. Ohne Suchvolumen auf den Namen bleibt die Entität im Graph präsent, aber ohne SERP-Projektion.
Es gibt zudem Kategorien, in denen Google das Panel aktiv zurückhält, selbst bei hoher Konfidenz: Minderjährige, Personen mit laufenden rechtlichen Verfahren, Entitäten mit Reputations-Streitigkeiten und Personen in regulierten Branchen (Finanz, Medizin, Recht), bei denen die YMYL-Policy zusätzliche Verifikationsanforderungen stellt.
Die Panel-Emergenz-Fenster
In der dokumentierten Mehrheit beobachteter Panel-Emergenzen erschien das Panel in einem Zeitfenster von wenigen Wochen nach dem Wikidata-Eintrag - vorausgesetzt, drei unabhängige Authority-Quellen und das vollständige Schema waren bereits ausgerollt. Wer diese Reihenfolge umdreht (Wikidata zuerst, Schema später), erlebt typischerweise ein Fenster von 4 bis 9 Monaten. Die Reihenfolge ist kein Detail - sie ist der Beschleuniger.
Die 8-Schritte-Anleitung zum Knowledge Panel: dokumentiert und erweitert
Die folgende Sequenz ist die im Branchenkonsens dokumentierte Standardabfolge für den Aufbau eines Knowledge Panels - zurückgehend auf Googles eigene Hinweise in der Search Central Documentation (2023-2025), die Arbeiten von Aleyda Solis, die Kalicube-Methodik von Jason Barnard sowie die Patent-Analysen von Bill Slawski. Jeder der acht Schritte wird hier im Originaltext-Kern zusammengefasst und anschließend mit operativen Details aus der eigenen Beratungspraxis erweitert, damit der Schritt nicht als Checkliste, sondern als funktionaler Baustein lesbar bleibt.
Schritt 1: Verstehen, was Google tatsächlich will
Google vergibt Panels nicht als Gefallen. Ein Panel erscheint, wenn der Knowledge Graph genug Konfidenz hat, dass eine distinktive, notable Entität vorliegt. Diese Konfidenz stützt sich auf drei Säulen: Corroboration (mehrere unabhängige, autoritative Quellen bestätigen dieselben Fakten), Authority (Wikipedia, große Nachrichtenmedien, Fachpublikationen und etablierte Datenbanken als Ankerpunkte) und Structured Data (Schema-Markup auf Websites, das die Entität maschinenlesbar definiert).
Erweiterung: Dieses Prinzip ist in Googles Search Quality Rater Guidelines und in der offiziellen Google-Search-Central-Dokumentation zum Knowledge Graph bestätigt. Die operative Konsequenz ist unbequem, aber eindeutig: Panels sind das Symptom eines Vertrauensgewinns, kein Kauf-Produkt. Wer am Panel zu arbeiten versucht, arbeitet am falschen Endpunkt der Wertschöpfungskette. Korrekt ist die Arbeit an den drei Säulen, aus denen die Konfidenz entsteht.
Schritt 2: Aktuelle Online-Präsenz auditieren
Vor jedem Aufbau steht die Bestandsaufnahme: Was sieht Google heute? Inkognito-Suche nach dem eigenen Vollnamen. Existiert bereits ein Panel? Was dominiert Seite 1: LinkedIn, die eigene Website, News, oder nichts Belastbares? Gibt es Namens-Kollisionen mit anderen Trägern desselben Namens? Sind die Daten über Plattformen hinweg konsistent oder widersprechen sie sich bei Rolle, Firma oder Ort?
Erweiterung: Neben der manuellen SERP-Prüfung liefern Google Knowledge Graph Search API, Bing Entity Search, SERP-Tools wie Ahrefs/Semrush mit People-Graph-Ansicht sowie der Wikidata-Reconciliation-Service belastbare Signale. Name-Collision-Fälle, besonders bei häufigen türkischen Namen oder Allerweltsnamen, erfordern eine klare Disambiguation-Strategie: konsequent geführter Mittelname, akademischer Titel oder eine stabile Funktionsbezeichnung als Suffix.
Schritt 3: Die Entity-Home etablieren
Die Entity-Home ist die eine Seite, die Google als primäre Wahrheitsquelle über die Entität betrachtet, meistens die About-Seite der eigenen Website. Pflicht: Vollname im H1, eine professionell formulierte Bio (Wer, Was, Credentials, Affiliations), Links zu allen verifizierten Social-Profilen, ein hochwertiges Headshot und Schema.org Person mit Name, Jobtitel, Organisation, Social-Links und Bild.
Erweiterung: In 2026 reicht dieser Minimalumfang nicht mehr. Ergänzt werden sollten knowsAbout (Themen-Entitäten), alumniOf, award und hasCredential. Zudem muss die Seite unter einer stabilen, kanonischen URL liegen (Muster: /about/vorname-nachname/) und interne Links auf die knowsAbout-Zielseiten setzen. Das erzeugt Ko-Okkurrenz-Signale, die Google bei der thematischen Einordnung der Entität verarbeitet.
Schritt 4: Jedes Profil standardisieren
Google referenziert Informationen über Plattformen hinweg. Widersprüche wie „CEO at Acme Corp" (LinkedIn), „Founder, Acme" (Twitter) und „Managing Director, Acme Corporation" (Website) verwirren den Entity-Resolver. Standardisiert werden müssen: Name (gleiche Schreibweise, keine Abkürzungen), Titel, Firma, Kern-Bio-Fakten und Profilfoto. Typische Plattformen: LinkedIn, X/Twitter, Instagram, Facebook, YouTube, Crunchbase, Bloomberg (wenn anwendbar), eigene Website, Firmen-Bio, Branchendirektorien, Podcast-Gastprofile und Speaker-Bios. In der Praxis sind das 15 bis 25 Profile, also Stunden statt Minuten.
Erweiterung: Ein NAP-Register als strukturierte Tabelle (Google Sheet, CMDB, Notion-Datenbank) ist Pflicht, nicht Kür. Die Pflege läuft quartalsweise, flankiert von Namensmonitoring über Google Alerts und Mentionlytics. Jeder Drift-Fall wird nicht kommentiert, sondern an der Quelle korrigiert.
Schritt 5: Einen Wikidata-Eintrag bekommen
Wikidata ist das strukturierte Backbone hinter Wikipedia. Ein Wikipedia-Artikel ist nicht Voraussetzung für ein Knowledge Panel, ein verbreiteter Mythos. Ein Wikidata-Item aber sehr wohl. Das Item wird auf wikidata.org angelegt, die Claims (Name, Geburtsdatum, Beruf, Arbeitgeber, Website, Social-Profile) werden jeweils mit Referenzen aus unabhängigen Sekundärquellen belegt; self-published Quellen werden in der Regel abgelehnt. Risiko: Wikidata-Editoren können das Item wegen fehlender Notability löschen, und ein gelöschtes Item verschlechtert die Ausgangslage.
Erweiterung: Vor dem Anlegen erfolgt ein Notability-Check gegen die WD:Notability-Regeln (clearly identifiable conceptual or material entity plus mindestens eine valide externe Referenz oder structural need). Properties konsequent pflegen: P31 (instance of), P106 (occupation), P108 (employer), P856 (official website), P2003 (Instagram), P2013 (Facebook), P2002 (X/Twitter), P6379 (ORCID). Mehrsprachige Labels für alle Zielmärkte sind Standard, nicht Sonderfall.
Schritt 6: Presse und autoritative Erwähnungen aufbauen
Google braucht unabhängige Drittquellen, die die Fakten bestätigen. Die stärksten Signale: Fachartikel in Publikationen, denen Google vertraut (große Publikumsmedien, Branchenfachmedien), Interviews, Podcast-Features, Gastartikel, Branchendatenbanken (Crunchbase für Gründer, IMDb für Medienprofis), Berufsverbandslistungen. Google erkennt mittlerweile zuverlässig den Unterschied zwischen PR-only-Mentions und echter redaktioneller Coverage - ein echtes Feature in einer Branchenpublikation wiegt mehr als 20 Press Releases.
Erweiterung: Redaktionelle Coverage folgt dem Beitragswert-Prinzip: exklusive Daten, Primärforschung, pointierte Meinung. Zielmedien lassen sich nach Domain-Authority und redaktioneller Reichweite priorisieren. Gastbeiträge in fachlich einschlägigen Publikationen (für SEO-Themen etwa Search Engine Land, Search Engine Journal, t3n, OMR) bauen Topical-Authority parallel zur Entität auf und verankern die Person in der semantischen Nachbarschaft ihres Fachs.
Schritt 7: Technische SEO-Signale implementieren
Über die Entity-Home hinaus sind technische Signale Pflicht: sameAs-Properties im Schema, die auf alle verifizierten Profile zeigen; NAP-Konsistenz über alle Business-Listings; Google Search Console für die Website verifiziert; korrekte Crawlbarkeit (kein noindex auf Kernseiten); Sitelinks-Searchbox-Markup, wo sinnvoll.
Erweiterung: Ergänzend wird Organization mit Person über worksFor verkettet, Article-Schema nutzt author-Referenz (@id) auf den Person-Knoten, ImageObject kommt als image-Property mit width, height und caption. Google Merchant Center und Google Business Profile sind zu verifizieren, falls anwendbar; Bing Webmaster Tools und Bing Places komplettieren die Maschinenlesbarkeit. Crawl-Budget: die Entity-Home muss eine niedrige Click-Tiefe haben, maximal zwei Klicks von der Startseite.
Schritt 8 - Warten (und hoffen)
Auch bei korrekter Ausführung gibt es keine Garantien. Google recrawlt und reverarbeitet nach eigenem Zeitplan. Für manche Entitäten dauert die Panel-Emergenz vier bis sechs Monate, für andere sechs bis zwölf. Name-Collisions oder unzureichende Authority können selbst nach vollständiger Umsetzung ein Panel verhindern. Shortcuts - spammiges Link-Building, Fake-Presse, gekaufte Wikipedia-Edits - können ein Panel kurz auslösen und dann zum Delete führen, und ein gelöschtes Panel ist deutlich schwerer wieder aufzubauen als ein nie erschienenes.
Erweiterung: Die Wartezeit ist kein passives Intervall, sondern eine aktive Verstärkungsphase. Sie umfasst Content-Produktion mit konsistenten Entity-Ko-Okkurrenzen, fortlaufende Pflege des Wikidata-Items, wöchentliches Tracking der Google-Knowledge-Graph-API-Antworten und kontrollierte Expansion der Drittquellen. Bleibt das Panel nach rund neun Monaten aus, folgt ein Notability-Re-Audit durch einen neutralen Dritten - in der Regel identifiziert dieser Audit präzise die Schicht (Corroboration, Authority oder Structured Data), auf der die Konfidenz unter Schwelle bleibt.
Das 6-Monats-Protokoll: Entity-Trust aufbauen statt Panel jagen
Das folgende Protokoll ist die verdichtete, monatlich getaktete Rollout-Version der acht Schritte oben - kondensiert für die Onboarding-Sequenz mit Personal Brands und mittelständischen Organisationen. Es ist bewusst monatlich strukturiert, nicht weil jeder Schritt einen Monat dauert, sondern weil die Reifungszeit zwischen den Schritten für Googles Crawl- und Verifikations-Zyklen notwendig ist.
- Monat 1 - Entity-Audit und Name-Collision-Check. Bestehenden Knowledge-Graph-Footprint prüfen (Google KG Search API, Search-Operator-Sampling). Name-Collision-Matrix aufstellen: alle Namensträger mit öffentlicher Sichtbarkeit, Gewichtung ihrer jeweiligen Entity-Trust-Scores. Disambiguation-Strategie festlegen (Mittelname verwenden, akademischen Titel konsistent führen, Berufsbezeichnung als Suffix etablieren).
- Monat 2 - Schema.org Person/Organization implementieren. Person- oder Organization-Schema mit vollständigem sameAs-Cluster auf der eigenen Domain ausrollen. Dedizierte Personenseite (
/about/max-muster/) mit@id-Anker. Parallel NAP-Daten auf 15 bis 25 autoritativen Profilen spiegeln. Jedes Profil: gleiches Foto, gleicher Name, gleiche Rolle, gleicher Firmen-Link. - Monat 3 - Wikidata-Fundament setzen. Wikidata-Eintrag mit Q-ID anlegen, Referenzen aus unabhängigen Sekundärquellen hinterlegen, Properties sauber pflegen (P31, P106, P1416, P856). Externe IDs (ORCID, LinkedIn-URL, Crunchbase) verknüpfen. Mehrsprachige Labels für relevante Märkte ergänzen.
- Monat 4 - Corroboration über autoritative Medien. Mindestens drei unabhängige Fachmedien mit konsistenten Fakten (Rolle, Firma, Ort, Laufbahn). Kein Pay-for-Placement. Fokus auf Branchenpublikationen mit redaktioneller Substanz und eigenem Schema.org-Author-Block.
- Monat 5 - Authority-Signale verdichten. Speaker-Rollen auf Konferenzen, Gremien-Mitgliedschaften, Autorenschaft in Fachzeitschriften, Zitationen in Studien. Jedes Signal mit maschinenlesbarem Fingerabdruck - Referentenprofile mit Author-Schema, Podcast-Einträge mit strukturierter Gästeliste, GitHub-/ORCID-/Google-Scholar-Verknüpfungen.
- Monat 6 - Monitoring und Entity-Drift-Kontrolle. Quartalsweise Google-Knowledge-Graph-API-Check. Monitoring von Drittanbieter-Datenbanken auf fehlerhafte Fakten. Bei Entity-Drift (falsches Foto, veraltete Position, Namens-Kollision) kontrollierte Korrektur über Quell-Update - nie über Panel-Feedback-Formular allein.
Das Protokoll ist bewusst frei von „Panel-Trigger-Tricks". Jeder Schritt adressiert eine der sechs Trust-Schichten. Wenn das System hält, erscheint das Panel als Nebenprodukt. Wenn es nicht erscheint, ist das diagnostisch wertvoll: Eine Schicht ist schwach, und der Audit zeigt, welche.
Grenzen, Risiken und ehrliche Erwartungen
Kein Protokoll garantiert ein Panel. In der Beratungspraxis mit Führungskräften aus DACH und international erschien in der Mehrheit der sauber umgesetzten Cases ein Panel; die Fälle ohne Panel-Emergenz teilen sich in zwei Gruppen: unzureichende Notability (keine belastbaren Sekundärquellen im Sinne der Wikidata-Kriterien) und hohe Name-Collision mit bereits etablierten Trägern desselben Namens, bei denen Disambiguation mehr Zeit benötigt als das Beobachtungsfenster.
Ehrlicher als die „Garantie"-Rhetorik ist die Erwartungsformulierung: Ein sauberes Protokoll hebt die Panel-Wahrscheinlichkeit von einem sehr niedrigen Ausgangsniveau auf ein qualitativ belastbares Niveau, typischerweise mit einem Zeitfenster von mehreren Monaten bis zu rund einem Jahr (Kalicube Pro spricht in öffentlichen Präsentationen von vergleichbaren Größenordnungen). Präzisere Zahlen ohne kontrollierte Studienbasis sind Marketing. Der reale Mehrwert liegt sekundär: Auch wenn kein Panel entsteht, resultiert aus der Arbeit eine messbar höhere AI-Citation-Rate, wie sie in Prompt-Level-SEO dokumentiert ist, und bessere Performance in AI Overviews.
Reputations-Kopplung: Panel und LLM-Vertrauen laufen parallel
Ein strategischer Nebeneffekt wird oft übersehen. Der Entity-Trust-Aufbau, der das Panel als Nebenprodukt erzeugt, erhöht gleichzeitig die Wahrscheinlichkeit, dass LLMs (ChatGPT, Claude, Gemini, Perplexity) die Entität korrekt modellieren und in Antworten zitieren. Die Trainingspipelines dieser Modelle pipen Wikidata, Wikipedia, strukturierte Daten und autoritative Medien in die Embedding-Schichten. Der Knowledge-Graph-Aufbau ist damit zugleich LLM-Grounding.
Für Senior-Brands heißt das: Das Budget für Entity-Trust-Arbeit wird zweifach verzinst - in Google-Sichtbarkeit (Panel, AI Overviews, Knowledge-Graph-basierte Features) und in LLM-Sichtbarkeit (korrekte Fakten in generativen Antworten, niedrigere Halluzinationsrate im eigenen Kontext). Operativ flankieren wir diese Arbeit mit Online-Reputation-Management, siehe die Leistungsseite Online Reputation.
Fazit: Die Frage, die Sie stattdessen stellen müssen
Nicht: „Wie bekomme ich ein Knowledge Panel?" Diese Frage produziert Shortcuts, die nur kurz halten und danach den Re-Entry für einen erheblich längeren Zeitraum blockieren. Sondern: „Wie stabil ist meine Entität im Weltmodell, das Google aus Wikidata, autoritativen Quellen und strukturierten Daten rekonstruiert - und was fehlt ihr noch, um eindeutig zu sein?"
Diese zweite Frage ist unbequem, weil sie Arbeit verlangt, die nicht als Panel sichtbar wird, sondern als Fundament. Aber sie ist die einzige Frage, die ein nachhaltiges Panel erzeugt - als Nebenprodukt, nicht als Ziel. Wer sie konsequent beantwortet, besitzt nicht nur ein Knowledge Panel. Er besitzt eine Entität, die Google, Bing, ChatGPT, Claude und Gemini in der nächsten Dekade konsistent korrekt repräsentieren werden. Das ist kein Feature. Das ist strategisches Terrain.