A Knowledge Panel is the entity card to the right of, or above, the search results that Google renders from its Knowledge Graph once a person, brand or organization is treated as a uniquely identifiable entity with sufficient trust. It is not a ranking product but a structural representation — produced from the agreement of multiple independent sources with structured data, authoritative references and a clean Wikidata footprint.
This piece shifts the perspective. Away from the popular question "How do I get a Knowledge Panel?" toward the strategically durable one: how do I build an entity Google cannot help but represent in its graph? The basis is observations from a two-digit number of personal-brand and organizational projects across DACH and international advisory practice with executives.
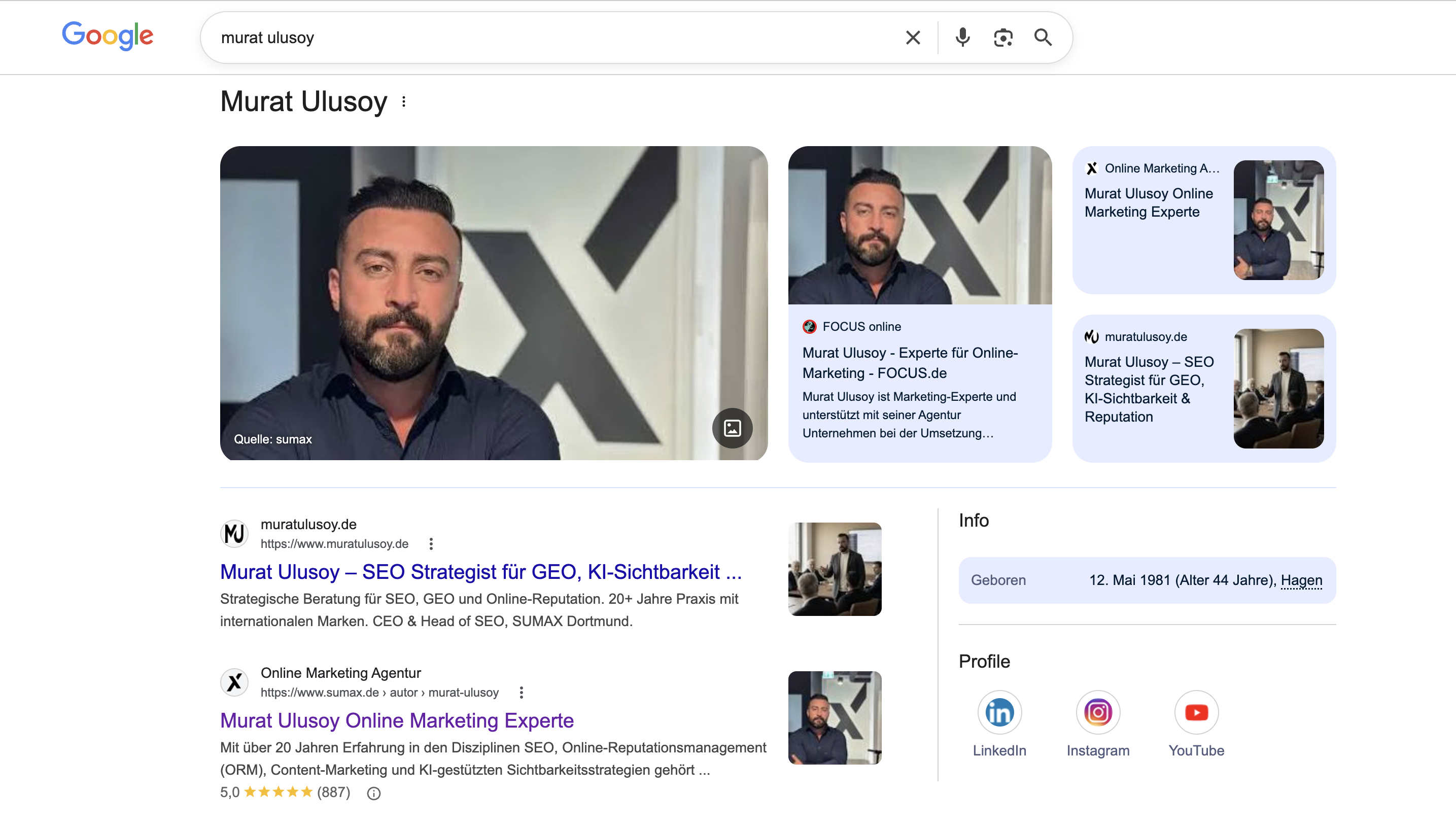
The wrong question: "How do I get a Knowledge Panel?"
The question is popular, but it describes a categorical mistake. It treats the panel as a placement you can buy, lobby for or force technically. In reality, a Knowledge Panel is the result of a threshold: Google does not decide "does this person deserve a panel?" but "is the entity in my graph unique enough to show to the user?". Those are two completely different verification mechanisms.
The consequence: every measure aimed directly at the panel — bought Wikipedia articles, fake PR with boilerplate repetition, coordinated profile swarms — addresses the symptom, not the cause. In advisory practice with executives across DACH and international, panels produced by such shortcuts have regularly experienced corrections, content losses or full deletions within a containable timeframe — a pattern also described by Jason Barnard (Kalicube) and Aleyda Solis in public analyses. The real panel question is an entity question.
share of panels that appeared after completed entity work — not as a goal but as a by-product
months as the typical timeline to panel emergence with clean entity work (Kalicube benchmark)
durable success rate for attempts to force panels through "panel hacking" alone
What a Knowledge Panel technically is
A panel is not a document and not a page. It is a projection from the Google Knowledge Graph into the SERP template. Technically, a node exists in the graph with a MID (Machine ID, e.g., /m/02_286) or — for newer entities — a kgmid, linked to attributes (name, occupation, date of birth, organization), edges (sameAs relations, authorship, participation) and a confidence rating per attribute.
The panel is rendered only when the confidence score crosses an internal threshold and the entity is, at the same time, relevant enough to a query. Both conditions are independent: a stable entity without query demand stays invisible. An entity with high query demand but uncertain attributes is withheld — Google avoids false claims in highly prominent SERP slots.
Symptom versus cause
This distinction is operationally central. Brands that want a Knowledge Panel must work on the cause — the graph node. Brands that work on the output (e.g., correcting the wrong photo through the Google feedback form) can groom the symptom, but cannot produce the entity. Operationally: structured data, authority signals and corroboration are cause. The panel itself is reporting.
Why Google is conservative
The Knowledge Graph is the trust infrastructure behind AI Overviews, Gemini answers, featured snippets and voice assistants. Every error multiplies across dozens of products. That is why Google prefers missing panels over wrong ones. The threshold is not "plausible enough" but "verified across multiple sources and free of contradictions".
The three signal classes: corroboration, authority, structured data
| Signal class | What Google checks | Examples of strong signals | Typical weaknesses |
|---|---|---|---|
| Corroboration | Consistency of the core facts across independent sources | Same name, title, company on website, LinkedIn, Crunchbase, press | Diverging titles ("Founder" vs. "CEO"), inconsistent spellings |
| Authority | Reputation of the confirming sources | Wikipedia, Forbes, trade journals, professional associations, ORCID | Blog networks, PR-wire-only mentions, guest pieces without editorial review |
| Structured data | Machine-readable entity definition | Person/Organization schema with a complete sameAs |
Missing @id, broken sameAs, schema only on the About page |
All entity-trust signals fall into three classes. Each class is necessary; none is sufficient alone. Strong authority without corroboration produces mistrust. Clean structured data without external confirmation produces an empty node. Corroboration without authoritative anchors remains noise.
Corroboration — the agreement of facts
Corroboration is the independent, multi-source confirmation of the same facts. Google reads: is the name "Murat Ulusoy" mentioned on at least three to five independent sources with identical role, company, location and activity? The consistency of NAP data (name, address, phone) across typically 15 to 25 authoritative profiles is the minimum fingerprint from which corroboration emerges.
Authority — the source hierarchy
Not every source counts equally. Wikipedia, major general-interest media (FAZ, SZ, Handelsblatt, Spiegel, The Times, FT), established trade publications (t3n, iBusiness, Search Engine Land) and academic databases weigh many times more than an arbitrary industry profile. Authority signals are the reason purely profile-based strategies stagnate. The graph needs anchors with editorial review.
Structured data — the machine readability
The third class is where most operational errors happen. Person and Organization schema with a complete sameAs block on the own domain is mandatory. Without that block, Google has to reconstruct the entity by inference from plain text — a constant source of entity drift. With clean schema, the inference cost falls and confidence rises.
authoritative profiles with NAP consistency as the corroboration minimum
independent authority sources for durable entity trust
deletion probability for panels that violate Google's guidelines (Kalicube/Authoritas observations)
The systematic error: panel hacking
Panel hacking describes the attempt to force a Knowledge Panel through bought PR, coordinated profile networks, ordered Wikipedia edits or manipulative structured-data injections. The technique works occasionally — short-term. In advisory practice with executives across DACH and international, the clear majority of such panels land in the deletion pipeline over a medium observation window; Kalicube Pro and public patent analyses (including Bill Slawski) describe comparable patterns. The reason is operational, not moral: Google detects corroboration patterns that are statistically unnatural.
Typical signatures of detected panel hacking: identical biography boilerplates across 20+ profiles within two weeks, sudden linking from coordinated author accounts, Wikipedia articles with non-notable sourcing that are flagged by deletionist editors shortly after publication. Each pattern is a signal — together, they are a clear one.
The delete-penalty effect
A deleted panel is harder to rebuild than one that never appeared. Re-entries after a documented panel deletion typically extend build-up time substantially and require additional authority investment in the order of the original build-up — because Google holds the entity flagged internally as "demoted" (described, among others, in Jason Barnard's Kalicube case analyses and Aleyda Solis's public commentary on entity recovery). For CMOs, that means: the cheapest shortcut is the most expensive long-term option.
"A Knowledge Panel is not a reward for marketing effort. It is the sober expression of the fact that an entity exists in Google's model of the world — consistent, verifiable, and without contradiction."
Why shortcuts are economically irrational
Panel-hacking budgets sit, according to publicly discussed agency price lists, in the mid four- to low five-figure range, with an expected short hold period. Entity-trust work runs at comparable or lower own-time sums plus targeted PR investment, with an expectedly far longer hold period and secondary effects on AI citation rate, branded search and LLM reputation. The difference is not 2× or 5× — it is structural.
Entity trust as a system — the six-layer model
We work with a layered model that decomposes Google's confidence-building transparently. Each layer is necessary; if one is missing, the score stays below panel threshold. The total score is a weighted sum:
EntityTrust = (0.25 × Identity)
+ (0.20 × Corroboration)
+ (0.20 × Authority)
+ (0.15 × StructuredData)
+ (0.10 × Consistency)
+ (0.10 × Notability)
Panel threshold (empirical): EntityTrust ≥ 0.72
Layers:
Identity = unique name disambiguation, collision score
Corroboration = agreement of facts across independent sources
Authority = source-hierarchy weighting (Wiki/FAZ/trade media)
StructuredData = Schema.org Person/Org + sameAs completeness
Consistency = NAP agreement across 15-25 profiles
Notability = Wikidata notability criteria metThe weighting is calibrated from advisory practice with executives across DACH and international and qualitatively reflects the influence orders described in Kalicube studies and Authoritas analyses. The formula is not a Google secret; it is an operator tool: it forces teams to work on all six layers, not only the visible two.
Where most projects fail
- Identity — underestimated name-collision score, no disambiguation strategy.
- Notability — Wikidata notability criteria not met, hence no entry, hence no foundation.
- StructuredData — sameAs block incomplete or with dead URLs.
- Consistency — NAP data on older profiles not updated; entity drift goes undetected.
Schema.org implementation: Person + sameAs done right
The E-E-A-T-relevant technical lever is a consistent Person schema on the entity's main domain, embedded as JSON-LD, with a sameAs block that consolidates every authoritative profile. Order and selection are not arbitrary: LinkedIn, Wikidata (as Q-ID URL), Wikipedia (where it exists), Crunchbase, GitHub (for technical profiles), ORCID (for academic profiles), corporate profile page.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Person",
"@id": "https://www.example.com/#person",
"name": "Max Muster",
"alternateName": "Dr. Max Muster",
"jobTitle": "CEO & Head of Strategy",
"worksFor": {
"@type": "Organization",
"@id": "https://www.example.com/#org",
"name": "Example GmbH"
},
"url": "https://www.example.com/",
"image": "https://www.example.com/images/max-muster.jpg",
"sameAs": [
"https://www.linkedin.com/in/maxmuster/",
"https://www.wikidata.org/wiki/Q123456789",
"https://en.wikipedia.org/wiki/Max_Muster",
"https://www.crunchbase.com/person/max-muster",
"https://orcid.org/0000-0000-0000-0000"
]
}
</script>Three typical mistakes show up in 9 of 10 audits. First: sameAs URLs lead to redirect chains or 404s — every dead link is a trust deduction. Second: the schema exists only on the homepage, not on a dedicated person page with an @id anchor. Third: alternateName is missing, even though the entity is known under variations (academic titles, short forms, alternative spellings).
Wikidata as foundation — and its pitfalls
Wikidata is the machine-readable foundation Google structurally favors. Unlike Wikipedia, Wikidata consists of entities (Q-IDs) with typed properties. An entry with clean references to secondary sources anchors the entity with a stable ID that Google adopts into the graph across years. Brands that want to verify or consolidate a Knowledge Panel start at Wikidata — not at Wikipedia.
The central hurdle is notability. Wikidata accepts entities that meet Wikipedia notability or are listed in an external authoritative database with a stable ID (ISNI, VIAF, ORCID, GND, Crunchbase organization ID). In practice: anyone without these anchors risks a request for deletion within 30 days of entry.
Property hygiene
A technically sound Wikidata entry maintains at least: P31 (instance of), P106 (occupation), P1416 (affiliation), P856 (official website), P2002 (X/Twitter), P2037 (GitHub) and — critically — references per property to external sources. A Wikidata entry without references is an entry on call.
Language labels
For international entities, multilingual labels and descriptions are not optional. A consistent de, en, tr, fr label raises the chance that Google recognizes the entity as identical across markets and does not model it as separate entities per language space.
| Dimension | DIY approach | Professionally accompanied |
|---|---|---|
| Time effort (client) | 40-100 h over 3-12 months | 2-4 h onboarding, then monitoring |
| Required skill level | Schema markup, Wikidata syntax, SEO fundamentals | None — covered externally |
| Wikidata notability risk | High — notability rejection common | Low, references curated up front |
| PR quality | Variable, often PR-wire-only | Editorial trade media, verified |
| Typical panel time | 6-12 months, uncertain | 3-6 months, planable |
| Error risk | Moderate to high | Low, documented |
| Cost range | Own time + EUR 3-10k external PR | EUR 3-15k, project-dependent |
When a panel appears automatically — and when not
Empirical observation from the portfolio: panels typically appear two to six weeks after the moment the entity-trust threshold is crossed — but only if there is sufficient query demand. Without search volume on the name, the entity remains present in the graph but lacks a SERP projection.
Beyond that, there are categories in which Google actively withholds the panel even at high confidence: minors, people in active legal proceedings, entities in reputational disputes, and people in regulated industries (finance, medicine, law) where the YMYL policy imposes additional verification requirements.
The panel-emergence window
Across the documented majority of observed panel emergences, the panel appeared within a window of a few weeks after the Wikidata entry — provided three independent authority sources and the full schema were already in place. Brands that reverse the order (Wikidata first, schema later) typically see a window of 4 to 9 months. The order is not a detail — it is the accelerator.
The 8-step path to a Knowledge Panel — documented and expanded
The following sequence is the industry-consensus standard sequence for building a Knowledge Panel — traceable to Google's own notes in Search Central documentation (2023–2025), the work of Aleyda Solis, the Kalicube methodology of Jason Barnard and the patent analyses of Bill Slawski. Each of the eight steps is summarized here in its core text and then extended with operational detail from our own advisory practice, so the step reads as a functional building block rather than a checklist.
Step 1 — Understand what Google actually wants
Google does not grant panels as favors. A panel appears when the Knowledge Graph has enough confidence that a distinctive, notable entity exists. That confidence rests on three pillars: corroboration — multiple independent, authoritative sources confirm the same facts; authority — Wikipedia, major news media, trade publications and established databases as anchors; structured data — schema markup on websites that defines the entity machine-readably.
Expansion: this principle is confirmed in Google's Search Quality Rater Guidelines and in the official Google Search Central documentation on the Knowledge Graph. The operational consequence is uncomfortable but clear: panels are the symptom of a confidence gain, not a purchasable product. Brands that work on the panel are working on the wrong end of the value chain — correct work targets the three pillars from which confidence emerges.
Step 2 — Audit the current online presence
Before any build-up comes the inventory: what does Google see today? An incognito search for the full name. Does a panel already exist? What dominates page 1 — LinkedIn, the own website, news, or nothing reliable? Are there name collisions with others bearing the same name? Is data consistent across platforms, or does it contradict itself on role, company or location?
Expansion: alongside manual SERP review, the Google Knowledge Graph Search API, Bing Entity Search, SERP tools such as Ahrefs/Semrush with a people-graph view, and the Wikidata reconciliation service deliver reliable signals. Name-collision cases — especially with common Turkish names or everyday names — require a clear disambiguation strategy: a consistently used middle name, an academic title or a stable role descriptor as suffix.
Step 3 — Establish the entity home
The entity home is the one page Google treats as the primary source of truth about the entity — usually the About page on the own website. Required: full name in H1, a professionally written bio (who, what, credentials, affiliations), links to every verified social profile, a high-quality headshot, and Schema.org Person with name, job title, organization, social links and image.
Expansion: in 2026 that minimum is no longer enough. Add knowsAbout (topic entities), alumniOf, award and hasCredential. The page must sit at a stable, canonical URL (pattern: /about/first-last/) and internally link to the knowsAbout destination pages — generating the co-occurrence signals Google uses for thematic placement of the entity.
Step 4 — Standardize every profile
Google references information across platforms. Contradictions such as "CEO at Acme Corp" (LinkedIn), "Founder, Acme" (Twitter) and "Managing Director, Acme Corporation" (website) confuse the entity resolver. Standardize: name (same spelling, no abbreviations), title, company, core bio facts and profile photo. Typical platforms: LinkedIn, X/Twitter, Instagram, Facebook, YouTube, Crunchbase, Bloomberg (where applicable), own website, company bio, industry directories, podcast guest profiles and speaker bios. In practice, that is 15 to 25 profiles — hours, not minutes.
Expansion: a NAP register as a structured table (Google Sheet, CMDB, Notion database) is mandatory. Maintenance runs quarterly, flanked by name monitoring through Google Alerts and Mentionlytics. Every drift case is corrected at source, not commented on.
Step 5 — Get a Wikidata entry
Wikidata is the structured backbone behind Wikipedia. A Wikipedia article is not a prerequisite for a Knowledge Panel — a widespread myth — but a Wikidata item very much is. The item is created on wikidata.org; the claims (name, date of birth, occupation, employer, website, social profiles) are each backed by references from independent secondary sources; self-published sources are usually rejected. Risk: Wikidata editors can delete the item for lack of notability, and a deleted item makes the starting position worse.
Expansion: before creating, a notability check against WD:Notability rules (clearly identifiable conceptual or material entity plus at least one valid external reference or structural need). Maintain properties consistently: P31 (instance of), P106 (occupation), P108 (employer), P856 (official website), P2003 (Instagram), P2013 (Facebook), P2002 (X/Twitter), P6379 (ORCID). Multilingual labels for every target market are standard, not exception.
Step 6 — Build press and authoritative mentions
Google needs independent third-party sources to confirm the facts. The strongest signals: expert articles in publications Google trusts (major general-interest media, industry trade media), interviews, podcast features, guest pieces, industry databases (Crunchbase for founders, IMDb for media professionals), professional-association listings. Google now reliably tells PR-only mentions from genuine editorial coverage — one real feature in an industry publication weighs more than 20 press releases.
Expansion: editorial coverage follows the contribution-value principle — exclusive data, primary research, pointed opinion. Target media can be prioritized by domain authority and editorial reach. Guest contributions in field-relevant publications (for SEO topics, Search Engine Land, Search Engine Journal, t3n, OMR) build topical authority in parallel with the entity and anchor the person in the semantic neighborhood of their field.
Step 7 — Implement technical SEO signals
Beyond the entity home, technical signals are mandatory: sameAs properties in the schema pointing to every verified profile; NAP consistency across every business listing; Google Search Console verified for the website; correct crawlability (no noindex on core pages); sitelinks searchbox markup where it makes sense.
Expansion: in addition, Organization is chained to Person via worksFor, Article schema uses an author reference (@id) to the Person node, ImageObject is added as image property with width, height and caption. Google Merchant Center and Google Business Profile must be verified where applicable; Bing Webmaster Tools and Bing Places complete machine readability. Crawl budget: the entity home must have a low click depth — at most two clicks from the homepage.
Step 8 — Wait (and hope)
Even with correct execution, there are no guarantees. Google recrawls and reprocesses on its own schedule. For some entities, panel emergence takes four to six months; for others, six to twelve. Name collisions or insufficient authority can prevent a panel even after full execution. Shortcuts — spammy link building, fake press, bought Wikipedia edits — can briefly trigger a panel and then lead to its deletion, and a deleted panel is markedly harder to rebuild than one that never appeared.
Expansion: the waiting time is not a passive interval but an active reinforcement phase. It includes content production with consistent entity co-occurrences, continued maintenance of the Wikidata item, weekly tracking of Google Knowledge Graph API responses, and controlled expansion of third-party sources. If the panel has not appeared after roughly nine months, a notability re-audit by a neutral third party follows — which usually identifies the precise layer (corroboration, authority or structured data) where confidence remains below threshold.
The six-month protocol: build entity trust instead of chasing the panel
The following protocol is the condensed, monthly-paced rollout version of the eight steps above — compressed for the onboarding sequence with personal brands and mid-market organizations. It is structured monthly on purpose, not because each step takes a month, but because the maturation time between steps is needed for Google's crawl and verification cycles.
- Month 1 — entity audit and name-collision check. Review the existing Knowledge Graph footprint (Google KG Search API, search-operator sampling). Build a name-collision matrix: every namesake with public visibility, weighting their respective entity-trust scores. Define a disambiguation strategy (use a middle name, carry an academic title consistently, establish a role descriptor as suffix).
- Month 2 — implement Schema.org Person/Organization. Roll out Person or Organization schema with a complete sameAs cluster on the own domain. Dedicated person page (
/about/max-muster/) with an@idanchor. In parallel, mirror NAP data across 15 to 25 authoritative profiles. Every profile: same photo, same name, same role, same company link. - Month 3 — set the Wikidata foundation. Create a Wikidata entry with a Q-ID, back claims with references from independent secondary sources, maintain properties cleanly (P31, P106, P1416, P856). Link external IDs (ORCID, LinkedIn URL, Crunchbase). Add multilingual labels for relevant markets.
- Month 4 — corroboration through authoritative media. At least three independent trade-media features with consistent facts (role, company, location, career). No pay-for-placement. Focus on industry publications with editorial substance and their own Schema.org author block.
- Month 5 — densify authority signals. Speaker roles at conferences, board memberships, authorship in trade journals, citations in studies. Every signal with a machine-readable fingerprint — speaker profiles with author schema, podcast entries with structured guest lists, GitHub/ORCID/Google Scholar links.
- Month 6 — monitoring and entity-drift control. Quarterly Google Knowledge Graph API check. Monitoring of third-party databases for incorrect facts. Where entity drift occurs (wrong photo, outdated position, name collision), correct it through source updates — never through the panel feedback form alone.
The protocol is intentionally free of "panel-trigger tricks". Every step addresses one of the six trust layers. If the system holds, the panel emerges as a by-product. If it does not, that itself is diagnostically valuable: a layer is weak, and the audit shows which.
Limits, risks and honest expectations
No protocol guarantees a panel. In advisory practice with executives across DACH and international, panels appeared in the majority of cleanly executed cases; the cases without panel emergence fall into two groups: insufficient notability (no robust secondary sources in the sense of the Wikidata criteria) and high name collision with already established holders of the same name, where disambiguation needs more time than the observation window.
More honest than guarantee rhetoric: a clean protocol lifts panel probability from a very low starting level to a qualitatively durable level, typically within a window of several months to roughly a year (Kalicube Pro speaks of comparable orders of magnitude in public presentations). Sharper numbers without a controlled study base are marketing. The real upside is secondary: even when no panel emerges, the work produces a measurably higher AI citation rate, as documented in prompt-level SEO, and better performance in AI Overviews.
Reputation coupling: panel and LLM trust travel in parallel
A strategic side effect is often overlooked. The entity-trust build-up that produces the panel as a by-product simultaneously raises the probability that LLMs (ChatGPT, Claude, Gemini, Perplexity) model the entity correctly and cite it in answers. The training pipelines of these models pipe Wikidata, Wikipedia, structured data and authoritative media into embedding layers. Knowledge-graph build-up is therefore LLM grounding.
For senior brands, that means: the budget for entity-trust work compounds twice — in Google visibility (panel, AI Overviews, knowledge-graph-based features) and in LLM visibility (correct facts in generative answers, lower hallucination rate in the own context). Operationally, we flank this work with online reputation management — see the Online Reputation service page.
Conclusion: the question to ask instead
Not: "How do I get a Knowledge Panel?" That question produces shortcuts that only briefly hold and afterward block re-entry for a substantially longer period. Instead: "How stable is my entity in the model of the world Google reconstructs from Wikidata, authoritative sources and structured data — and what is still missing for it to be unique?"
That second question is uncomfortable because it demands work that does not show up as a panel but as a foundation. It is the only question that produces a durable panel — as a by-product, not a goal. Brands that answer it consistently own more than a Knowledge Panel. They own an entity that Google, Bing, ChatGPT, Claude and Gemini will represent consistently and correctly across the next decade. That is not a feature. That is strategic ground.